25 July 2023

In 2021, AWS WAF introduced a new CAPTCHA feature to help protect sites against bot traffic. The release had some mixed reviews but the idea was that it was an effective protection against programmatic solvers or “bots”.
In this post, I walk through my methodology for beating one of the CAPTCHA challenges presented programmatically. If you’d like to follow along, you can try the CAPTCHA challenges yourself here.
The CAPTCHA feature in AWS WAF is an optional action as a result of a match against customer-defined rules. It is intended to be an option to help bridge the difficult decision of a hard deny or hard allow when client heuristics may appear suspicious but not outright bot-like.
When triggered, the action prompts viewers of a website with interactive challenges designed to test that a human viewer is real and block bots seeking to crawl or disrupt human traffic. At launch, and to this day, there are two challenges available which I will call the “car maze” and “shape match” challenges.
I created a Twitter (𝕏?) thread about beating the car maze challenge when it was originally released which you can read here:
Had a bit of fun today with the WAF CAPTCHA thing. The car maze turned into a fun programming challenge! 1/ pic.twitter.com/D6Rf4SZGy4
— Ian Mckay (@iann0036) November 14, 2021
I will note that there have been some changes since writing the thread and discussing my findings with the AWS WAF service team that make the car maze challenge slightly more complex, though the same concepts still broadly apply.
Let’s go through the same process with the shape match challenge!
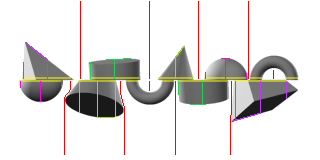
The shape match challenge features an image of 5 random 3D shapes lined up horizontally which has been split across the vertical axis and reordered. The interface gives you a slider which you can move to match usually only one shape at a time and gives you instructions as to which shape to match up and submit. The bottom section wraps as you drag the slider.
The available shapes are: ball, cone, cube, cylinder, donut, knot and pyramid.
The challenge presents both halves of the shapes as a single JPEG image, always at a 320x160 resolution. Taking a similar approach as the car maze solve, I’m using HTML canvas to inspect the image, extract pixel data and draw for my own visualization. For my first step, I sample the top-left pixel colour and eliminate these pixels from consideration. Because the challenge is a JPEG, some colour blending and artifacts are present so in most of the below steps I check for colour closeness by ensuring the RGB channels are within a small boundary (in this case, no more than 7 away). The top and bottom 80 pixels of the Y-axis represent the top and bottom sections, respectively.

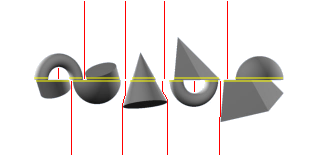
I now want to identify the location and width of the shapes at the midline for the top and bottom sections. The shapes in the challenge always have a clear separation between them, so in order to do this I move left-to-right at just above and below the midline (skipping the exact pixels on the midline, as JPEG artifacting can sometimes merge the pixels at y=79 and y=80). When I hit a non-background pixel, I mark the starting point of the shape. Once I hit a background pixel again, I can presume the start and stop points on the X-axis.
This gives me a set of values which intersect at the midline, however there are typically more values than the 5 shapes that are present. This is because shapes like the donut and knot intersect the midline at multiple points. To overcome this, we need to find any space in between where the shapes hit the midline where there isn’t a clear path to the relative extremes of the axis (i.e. where it is presumed to be in the center of the donut / knot). We take the middle of each of the clear spaces and start drawing a line towards the extreme of the axis, allowing a deviation to the left or right if clear space is present. Any line that does not reach the axis extreme is considered to be within the shapes, so these points are aggregated with regard to the shape boundary at the midline. This finally provides us with 5 positions and widths for both the top and bottom sections.
Because the donut always has two midline points which are of roughly equal width, we can mark this as a high probability match straight away. Additionally, if we see a single shape with more than 2 midline point intersections we can safely assume it is of the knot as this is the only shape that does this. At this point, I can start drawing the resulting shapes on individual canvases and mark those which are assumed during development.
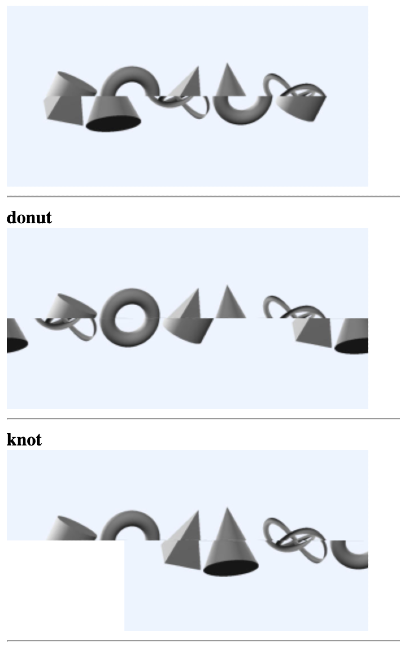
We can then use the widths of the top and bottom shape midline intersections and find roughly matching widths. This gives us strong candidates for matching top and bottom section shapes, allowing us to calculate the relative X-axis offset needed to create the shapes. Under good circumstances, we now have 5 completed shapes but no way of identifying at least 3 of them.
In order to discover more information about the potential shapes, we calculate more landmark points to gain additional heuristics on the shape type. These points are calculated by the following:
Here are the paths that discovery takes to find the landmark points:
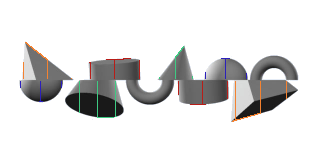
A ball shape always has a short Y-axis travel for points 1 and 2 for both sections, as well as a short X-axis travel from the center of the midline for points 3 and 4. The Y-axis travel for points 3 and 4 are generally identical and have roughly the same value as the X-axis travel for points 1 and 2.
A cone or pyramid shape typically also has a short Y-axis travel for points 1 and 2 in the top section, but a large Y-axis travel for all points in the bottom section.
A cube or cylinder generally has a roughly matching X-axis and Y-axis for the diametrically opposing points (point 1 in the top and point 2 in the bottom, and vice-versa).
Although it is challenging to decide between a cone/pyramid and cube/cylinder due to their shape similarities, there is one more trick we can use. Taking a path across the X-axis just below the midline, track the colours during movement. If the colour always gradually changes slightly, we can assume there is a gradient and the shape is a cone or cylinder. If there is exactly one or two colours, these represent the visible faces of a pyramid or cube.
We’ve now successfully identified each shape and their offsets.
The challenge generally accepts an offset value as its answer and so without any UI interference we could simply respond with a network request programmatically. However, I wanted to see the actual solution occur so I looked into actually performing the sliding action.
I had never programmatically moved a slider before and it turns out it is actually a rare automation to achieve, but it is possible. I came across this StackOverflow answer which showed I can create custom mousedown, mousemove and mouseup Mouse Events which worked in order to drag the slider. Notably, there was some math required to slide to the correct position, as the image width was 320 pixels, the slider would drag a maximum of 274 pixels, and the challenge solution endpoint accepted an answer between 0 and 255.
Occasionally, identification would fail due to an edge case or similar, however this simply meant that a new challenge would load and the automation could try again immediately. There seems to be no lockout or escalation of difficulty.
There were a few approaches I could have taken during the development of this solution, however I took what I thought was the simplest and easiest to understand solution. I did look into using the JavaScript version of OpenCV, which I could pretty easily use to find the contours of the shapes and I could have used this to assist with some edge case resolution.

Additionally, the audio-based accessibility CAPTCHA alternative still remains for those in the speech recognition space looking for a fun challenge.
The AWS WAF CAPTCHA remains an effective deterrent for all but the most determined of bot authors. I don’t envy the position the AWS WAF service team members are in. They are charged with creating a novel, interactive CAPTCHA challenge that has little cognitive load for users but remains challenging enough that it isn’t easily toppled by bots. I believe that if there were a constantly evolving rotation of new WAF challenge types we would have an effective protection purely based on the bot authors ability to adapt. Sadly this hasn’t yet happened. Features like Bot Control seem to be a far more effective way of dealing with bot traffic without generally affecting users, so I’d recommend that instead.
If you liked what I’ve written, or want to hear more on this topic, reach out to me on Twitter (or whatever it’s called now) at @iann0036.