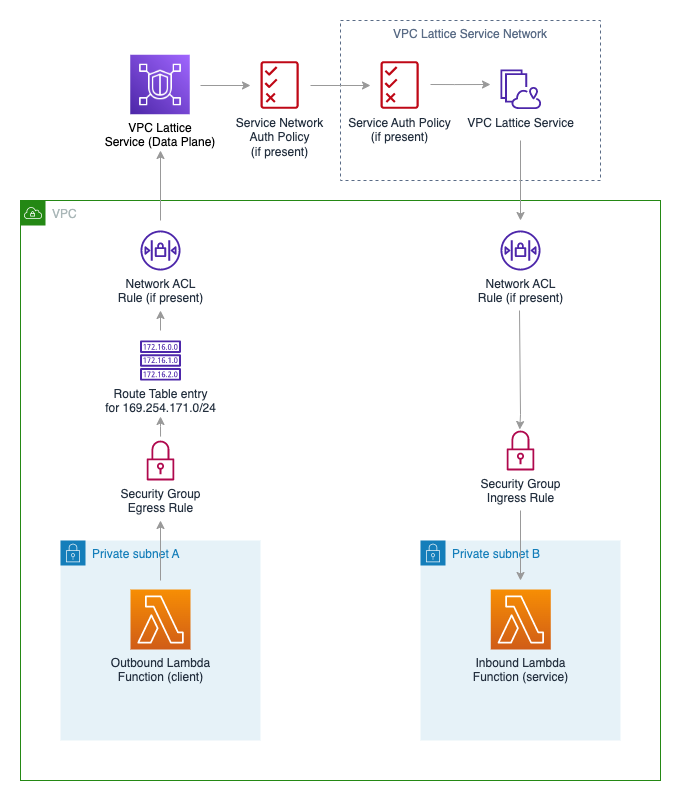
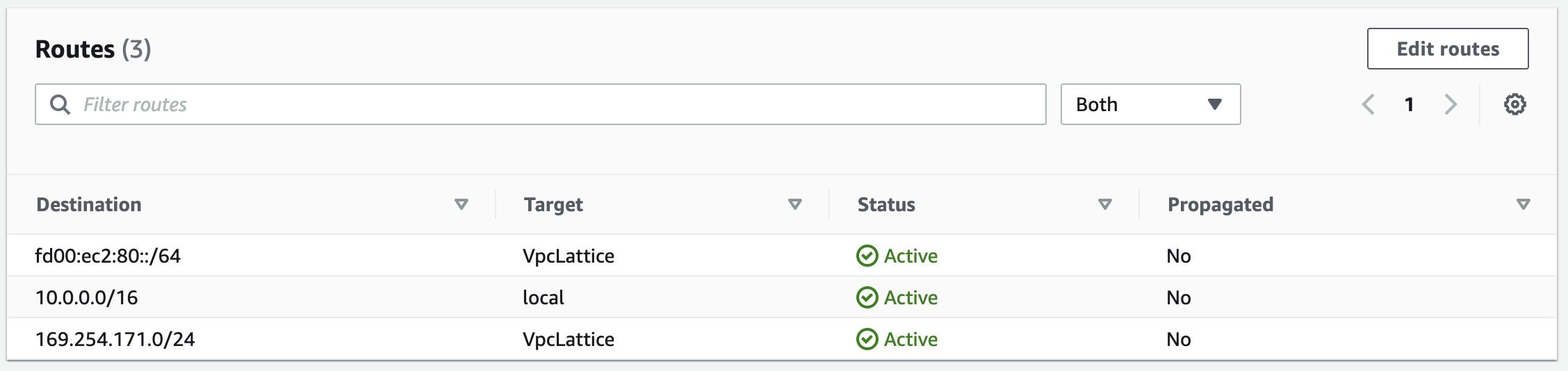
Cedar is a new language created by AWS to define access permissions using policies, similar to the way IAM policies work today. In this post, we’ll look at why this language was created, how to author the policies, and some additional features of the language. The language was designed by the Amazon automated reasoning team for use in new services such as Amazon Verified Permissions, AWS Verified Access and likely other future services and integrations.
Why write a new language?
IAM policies, introduced over 11 years ago, have been integrated into the AWS ecosystem as the fundamental way to control both human and system access to AWS resources. IAM policies are highly optimized for AWS and have constructs (like ARNs) which make it not suitable for usage on principals and resources outside of AWS.
Cedar is a generalist language which has no implicit AWS constructs within it, and this allows it to be used as an authorization engine for non-AWS applications. This is why it’s used at the core of the Amazon Verified Permissions service, where AWS manages the policy dataset and allows systems to directly make authorization calls against the evaluation engine. Incidentally, the name “Cedar” was coined as a follow on from the internal policy language of IAM, “Balsa”.
Cedar is written in Rust, which makes it run in milliseconds, and was designed to be simple to reason about the effect of policies. For example, it allows for the creation of tooling which takes two policies and determines whether they are exactly equivalent, or whether there are authorization requests that would differ in the result when evaluated against each policy.
How it works
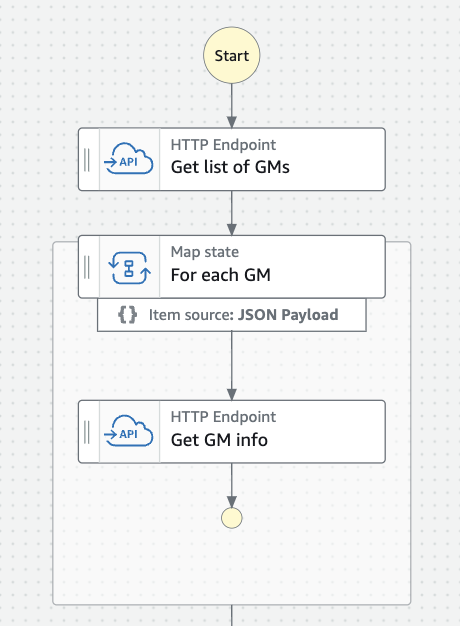
The policy evaluation engine for the Cedar language takes one or more policies, and evaluates whether a requested action is permitted or forbidden (allowed or denied). Cedar requires the principal making the request, the action being taken, the resource being accessed, and optionally additional request context at the time of the authorization call. Cedar also consumes the policies to be evaluated and may also use a list of entities (principals, actions and resources) that exist within your application, however these may be provided ahead of time or indirectly depending upon the service integration.
The request context object may be set by the requesting application or, in the case of AWS Verified Access, defined by the service.
Cedar has a playground which allows you to play with the engine itself. It is also currently integrated into the Amazon Verified Permissions and AWS Verified Access services. As of the time of writing, Cedar is not available as an open-source or otherwise downloadable library.
Syntax
A typical Cedar policy statement looks like the following:
permit(
principal == User::"John",
action == Action::"view",
resource
)
when {
resource in Folder::"John's Stuff" &&
context.authenticated == true
};
A policy can contain a number of statements by simply appending them onto the policy document. The syntax is not whitespace dependent and may be compressed into a single line. Typically, principals and resources should use immutable identifiers and not names. The examples in this post use simple names for readability purposes only.
The policy contains the following parts:
- The effect, which will always be either
permit or forbid
- The scope, which specifies the principals, actions, and resources to which the effect applies
- Optionally, condition clauses, which may either be a
when or an unless condition
Entities (principals, actions or resources) will always follow the format TypeOfEntity::"UniqueIdentifier". The type of entity may be further namespaced, for example, Company::Account::Department::Person::"John".
Entity types are ambiguous and not determined by their namespace. This means a single entity can be either a principal, action or resource, depending upon the specific context. The only exception is that actions must have their rightmost namespace use the keyword Action (i.e. Action::"MyAction", CustomNamespace::Action::"MyAction").
Evaluation logic
When evaluating a request, Cedar will consider all statements within the policy, and in the case of Amazon Verified Permissions, all policies provided in a policy store (as if it were one big policy). If any forbid statement matches the request, the request will be denied, regardless of any permit statements. If at least one permit statement matches the request (and no forbid statements match), the request will be allowed. If no statements match, the request will be implicitly denied.
If you’ve worked with AWS IAM, you’ll recognize Cedar’s policy evaluation logic is the same. This also means that ordering of statements in a policy is irrelevant and has no effect on the outcome of an authorization request.
Because forbid statements are applied universally without the ability to override, they are commonly used to craft guardrails across the entire policy store.
The scope
The scope is written in a way that almost looks like a set of arguments in a function. It always consists of the keywords principal, action and resource. Each of these keywords may optionally be followed by either an == Some::"Entity" or an in Some::"Group" to scope down the principals, actions or resources in which the statement applies to. In addition, an inline set in the form in [ Some::"Entity", SomeOther::"Entity", ... ] can be used for the action keyword only. When no keywords have this suffix, the policy applies to all requests, so long as the conditions are met.
The scope is generally used for role-based access control, where you would like to apply policies scoped to a specific defined or set of resources, actions, principals, or combination thereof.
Condition clauses
Condition clauses further limit whether a policy takes effect for the specific request. Typically policy statements will either have no condition clauses or one condition clause, however the syntax does allow for any number of condition clauses to form a statement.
Condition clauses are more flexible than the scope, featuring a basic set of operators to allow you to form a boolean result of acceptance based off of the principal, action, resource or context of the request, as well as the attributes or nested hierarchy of these entities where a list of entities has been defined. The use of logical operators such as && and || allow you to form long, complex conditions to match your specific requirements. The like operator allows you to perform string matching with the use of a * wildcard character.
Condition clauses are intended to perform attribute-based access control. Though it is possible to include scope conditions within a condition clause, exactly the way you would in the scope, it’s recommended that you retain those scope conditions in the scope for both readability and performance reasons.
Additional language features
Using the above syntax is all you need to start writing basic statements to permit or forbid access to your application, however there are some more features of the language which we’ll go through. Some of these features may not be available or useful depending upon the service in which Cedar is integrated into.
Policies may contain the // operator to add comments, which are particularly useful for indicating an abstract identifier, for example:
// the following was added by the accounts team
// it was approved by Jane Doe
permit(
principal == User::"9a6afab1-5a37-4c90-aa40-24277b93ca28", // John Smith
action,
resource == Account::"710f18bc-b8ab-4313-b362-8e6264cfcf91" // MyCorp Dev Account
);
Entities
Cedar supports accepting a list of known entities (resources, actions or principals) within a system. This is helpful as you may author policies which interact with the hierarchy or attributes of the entities within condition clauses. When an authorization request is made, the principal, action and resource identifiers will correlate to the defined entity of the same identifier when present in the entity list.
The structure of the entity list differs from service to service. In the Cedar playground, the entity list looks like the following:
[
{
"uid": "User::\"john\"",
"parents": [
"UserGroup::\"Staff\""
],
"attrs": {
"department": "Hardware Engineering",
"age": 30
}
},
{
"uid": "UserGroup::\"Staff\""
}
]
In Amazon Verified Permissions (for an IsAuthorized call), the same entity list would look like this:
[
{
"EntityId": {
"EntityType": "User",
"EntityId": "john"
},
"Parents": [
{
"EntityType": "UserGroup",
"EntityId": "Staff"
}
],
"Attributes": {
"department": {
"String": "Hardware Engineering"
},
"age": {
"Long": 30
}
}
},
{
"EntityId": {
"EntityType": "UserGroup",
"EntityId": "Staff"
}
}
]
We can use the known attributes in the entity to construct policies that permit or forbid access. For example:
permit(
principal,
action == Action::"Access",
resource == Room::"Drinks Lounge"
) when {
principal.age >= 18
};
This policy allows access only when the principal has the attribute “age”, and its value is equal to or greater than the number 18. If the age attribute wasn’t set, or the principal wasn’t defined at all in the entities list, this statement wouldn’t permit access.
The entities can also have the concept of a hierarchy, at any nesting level, to act based on this. For example:
permit(
principal,
action == Action::"Access",
resource == Room::"Common Area"
) when {
principal in UserGroup::"Staff"
};
This policy allows any entity which has a parent of the UserGroup::"Staff" entity access. Once again, if the entity isn’t defined or isn’t a child of UserGroup::"Staff", this statement wouldn’t permit access. The in operator applies to both direct children, as well as all descendants of those children. Additionally, the in operator also applies to the referenced parent, i.e. if the principal was UserGroup::"Staff" in the above example the policy would permit access.
Extensions
In addition to the base data types of strings, booleans, integers and sets/arrays, Cedar supports the additional data types of IP addresses, and decimals. These two data types can only be declared using a function call-like syntax, and can only be operated on using their in-built methods. These data types are known as extensions.
In the case of IP addresses, the syntax looks like the following:
permit(
principal,
action,
resource
) when {
ip(context.client_ip).isInRange("10.0.0.0/8")
};
The IP address type is created using the ip(...) syntax, and calls the isInRange(...) function to return a boolean. A similar effect is seen for the use of the decimal types:
forbid(
principal,
action,
resource
) when {
decimal(context.risk_score).greaterThan(decimal("7.2"))
};
Because Cedar does not allow any floating point types to be passed in, inputs must be in the form of a string (i.e. “8.24”). Decimal supports up to 4 digits after the decimal point.
Both extensions have a number of other methods available, all of which currently return a boolean result.
Policy templates
Policy templates is a Cedar feature useful for applying a common policy to a large group of principals or resources. A policy template allows you to add a variable substitution to the equality operators in the scope block for the principal and/or resource keywords. A policy template by itself is not effective, but allows policies to be created by simply providing the variable values instead of duplicating the full syntax. Policies generated from policy templates will automatically update if a policy template changes. A policy template may look like this:
permit(
principal == ?principal,
action == Action::"download",
resource in ?resource
) when {
context.mfa == true
};
The ?principal and ?resource keywords represent the variables that may be substituted. A policy created from this template would allow the principal to download all children of the resource when accessing using MFA.
Examples
The following is a set of examples to help you get started and understand the language.
Allow all
Policy:
permit(
principal,
action,
resource
);
This statement permits all requests. It may be restricted by forbid statements elsewhere in the policy set.
Deny all
Policy:
forbid(
principal,
action,
resource
);
This statement forbids all requests. It cannot be overridden and renders all other statements in the policy set useless.
Specific RBAC policy
Policy:
permit(
principal == Customer::"John",
action == Action::"checkout",
resource == CheckoutCounter::"12"
);
This statement allows customer “John” to checkout at checkout counter 12.
When condition clause
Policy:
permit(
principal,
action == Action::"connectDatabase",
resource == Database::"db1"
) when {
context.port == 5432
};
Context:
This statement allows any principal to connect to database “db1”, so long as the “port” attribute in their request context is 5432.
Unless condition clause
Policy:
permit(
principal,
action in [HTTPMethod::Action::"GET", HTTPMethod::Action::"POST", HTTPMethod::Action::"DELETE"],
resource
) unless {
[Viewer::"anonymous", Viewer::"unknown"].contains(principal) ||
context.waf_risk_rating >= 7
};
Context:
{
"waf_risk_rating": 8.5
}
This statement allows any principal to perform a HTTP GET, POST or DELETE against any resource unless they are identified as an anonymous or unknown viewer or their WAF risk rating is greater than or equal to 7.
IP and decimal usage
Policy:
permit(
principal,
action == HTTPMethod::Action::"GET",
resource
) when {
(
// local subnet or same machine
ip(context.http_request.client_ip).isInRange(ip("10.0.0.0/8")) ||
ip(context.http_request.client_ip).isLoopback()
) &&
decimal(context.risk_score).lessThan(decimal("6.5"))
};
Context:
{
"http_request": {
"client_ip": "10.0.1.54"
},
"risk_score": "4.7"
}
This statement allows any principal to perform a HTTP GET against any resource when their IP address is within the 10.0.0.0/8 or loopback CIDR range and the value of the string-encoded risk score is less than 6.5.
Entity attributes
Policy:
permit(
principal,
action == SecuritySystem::Action::"swipeCardAccess",
resource == Room::"Sydney Boardroom"
) when {
principal.location like "Sydney*" ||
principal.training.contains("All Access")
};
Entities:
[
{
"uid": "Employee::\"1453\"",
"attrs": {
"location": "Sydney East",
"training": [
"General"
]
}
},
{
"uid": "Employee::\"325\"",
"attrs": {
"location": "Los Angeles",
"training": [
"General",
"All Access"
]
}
}
]
This statement allows any principal to swipe card access to the Sydney Boardroom if their location attribute starts with “Sydney” or their training attribute contains the “All Access” item. Both employees 1453 and 325 would be permitted under this statement.
Entity attributes relationship
Policy:
permit(
principal,
action == HTTP::Action::"GET",
resource
) when {
resource.owner == principal.username
};
Entities:
[
{
"uid": "User::\"Josh\"",
"attrs": {
"username": "josh1"
}
},
{
"uid": "File::\"blogpost.txt\"",
"attrs": {
"owner": "josh1"
}
}
]
This statement allows any principal to HTTP GET a file which they have ownership of. The entity User::"Josh" would be permitted to perform a HTTP::Action::"GET" on the File::"blogpost.txt" entity.
Entity inheritance
Policy:
forbid(
principal,
action,
resource == Application::"oracle"
) unless {
principal in Group::"Admins"
};
Entities:
[
{
"uid": "User::\"Ian\"",
"parents": [
"Group::\"Admins\"",
"Group::\"Users\""
]
}
]
This statement forbids any principal to perform any action against the oracle application unless they are a part of the Admins group. The entity User::"Ian" would be exempt from this forbid statement.
Policy template
Policy Template:
permit(
principal == ?principal,
action == Action::"Connect",
resource == ?resource
);
Policy Variables:
principal: User::"Harry"
resource: VPN::"vpn1"
The policy created from the policy template allows the user Harry to connect to the VPN “vpn1”.
Wrapping up
The Cedar language is both excitingly new and comfortingly familiar. It opens a new world of possible use cases and, of course, a new set of challenges and considerations. I look forward to seeing how the language gets used in real world scenarios and the ways people will architect their applications around the services Cedar supports.
A big thank you to members from the identity and automated reasoning teams for helping answer some questions I had during the creation of this post. If you liked what I’ve written, or want to hear more on this topic, reach out to me on Twitter at @iann0036.
]]>