11 January 2022

The AWS JavaScript SDK supports Node.js, React Native and web browsers, but what if you’re running in a service worker? In this post, I’ll explain how I modified version 2 of the AWS JavaScript SDK to run within a service worker context.
For the Former2 project, I produce browser extensions for most major browsers in order to bypass the lack of CORS for the majority of AWS services. This means that I embed a copy of the AWS JavaScript SDK in order to make the calls needed via the browser extension, which has authority to ignore the lack of CORS.
The browser extensions use a “manifest”, which details the functionality of the extension and what actions are permitted. Google is sunsetting version 2 of the manifest for Google Chrome and requires all extensions to move to manifest version 3 by the end of 2022. Along with some structural differences, one of the major changes required is to move from background pages (logic that runs in the background of an extension) to service workers.
Service workers (which are a subset of JavaScript workers) have greater limitations than background pages, including the lack of access to the DOM and its features, as well as the replacement of XMLHttpRequest for fetch. Service workers will also move to an inactive state if unused in a short period of time, meaning initialized variable data isn’t persisted, though I’ve skipped talking about my specific remediations to this in this article (hint: use IndexedDB).
Version 3 of the AWS JavaScript SDK is written in a way that it’s supported in a service worker context, but version 2 does not due to a variety of reasons. If you’re already using version 3 of the SDK, or are starting development on a service worker from scratch using version 3, you won’t have a problem.
As the Former2 project heavily relies on the syntax of version 2 of the SDK, as well as the fact that the service calls a majority of available services in the SDK, I wanted to avoid a migration effort to version 3 of the SDK. Others with existing projects making heavy use of SDK version 2 that are seeking to move to service workers (or CloudFlare Workers) might also benefit from this.
Note that this is not an official change, and these changes could break current or future functionality in unintended ways, so I don’t recommend you use this in a production context.
After performing the changes to the browser extension manifest, my first issue was that the SDK script could no longer be directly loaded into the shared DOM model.
Before:
"background": {
"scripts": [
"aws-sdk-2.1046.0.js",
"bg.js"
]
},
After:
"background": {
"service_worker": "bg.js"
},
Service workers come with a way to load scripts using the importScripts() function. So I added the following to the top of my bg.js script:
importScripts("aws-sdk-2.1046.0.js");
This addition now silently failed the AWS calls I requested the extension make, without much debugging information.
It’s at this point that I’d like to call out Saurav Kushwaha for his prior work in this area, which overrides the XHRClient class used in the AWS namespace with fetch. I did need to perform a couple of slight modifications to properly return correct error codes however.
After replacing the XHRClient class, I was happy to see that some calls were successfully returning, but for some reason there was still some failures.
The failures I was seeing were coming from STS and S3, and I quickly realised that these were APIs that returned XML-based responses.
One immediate problem that actually showed error logs was that window was not defined, where parts of the SDK expected it to be available.

I quickly added a one-liner to make that available during initialisation:
if(!window){var window = {}};
After that change, I was now receiving an error that it could not load the XML parser.

Digging into the SDK, the logic looked like the following:
if (window.DOMParser) {
// use the native DOM parser library
} else if (window.ActiveXObject) {
// use the ActiveXObject to parse, a fallback for IE8 and lower
} else {
throw new Error("Cannot load XML parser");
}
The SDK relies on the native DOM parser to interpret XML responses from those services, so in order to alleviate this I decided to find a polyfill to replace it. I came across xmldom module on npm and found it suitable for my needs. I did need to bundle this into a browser-compatible library, so used browserify to achieve this.
After importing the new DOM parser library for use by the SDK, I re-tested the calls which produced a valid response end-to-end. All done, or so I thought.
Though my application now seemed to be working well, producing no errors and always returning valid responses, I noticed that many of my list calls (for example, S3.ListBucket) weren’t returning the resources within my account I expected.
I suspected some issues with the XML parser and dumped both the response of the HTTP call, and the object immediately after xmldom had parsed it. Both of these correctly showed the bucket names I was expecting, yet the response produced an empty array.
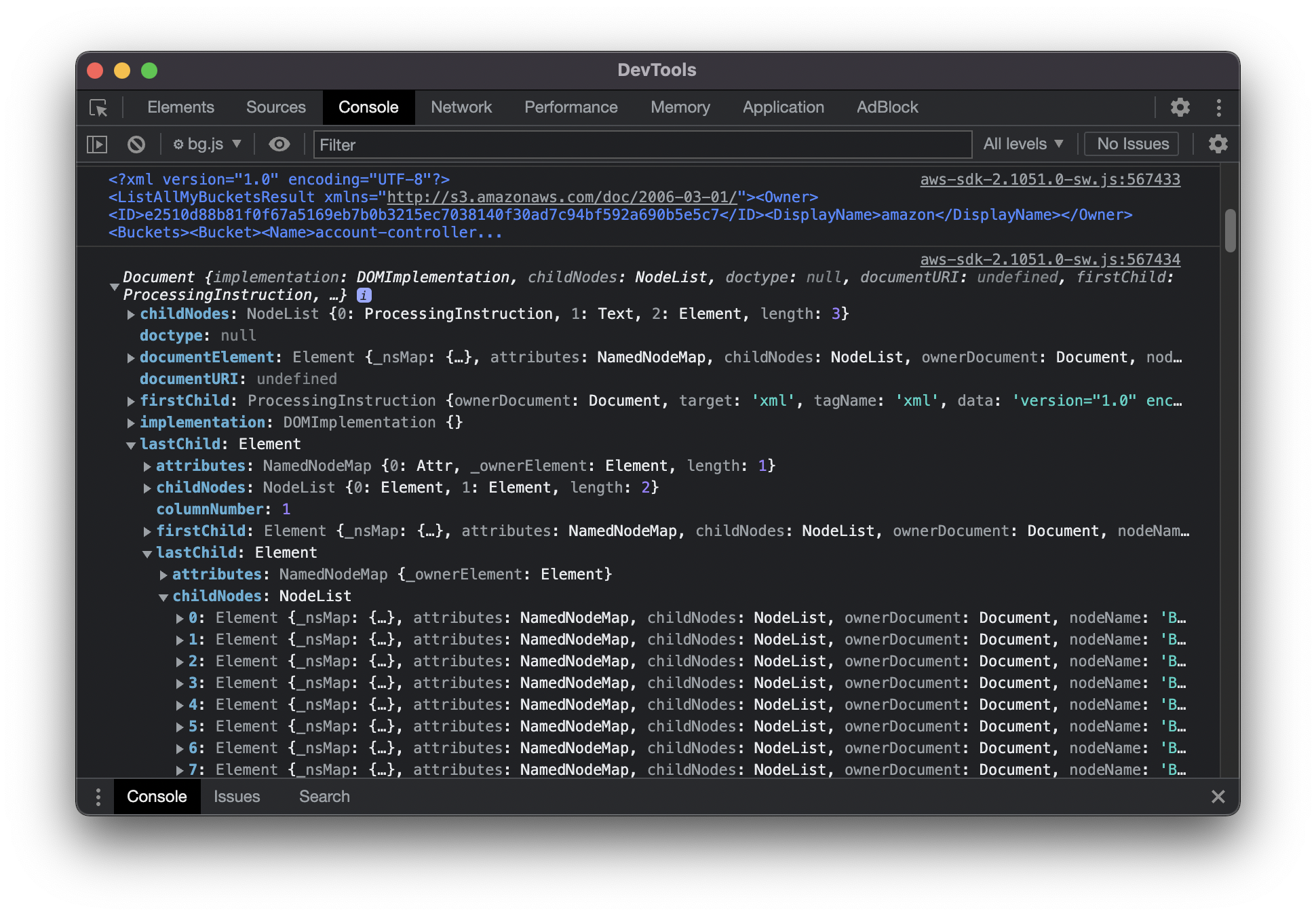
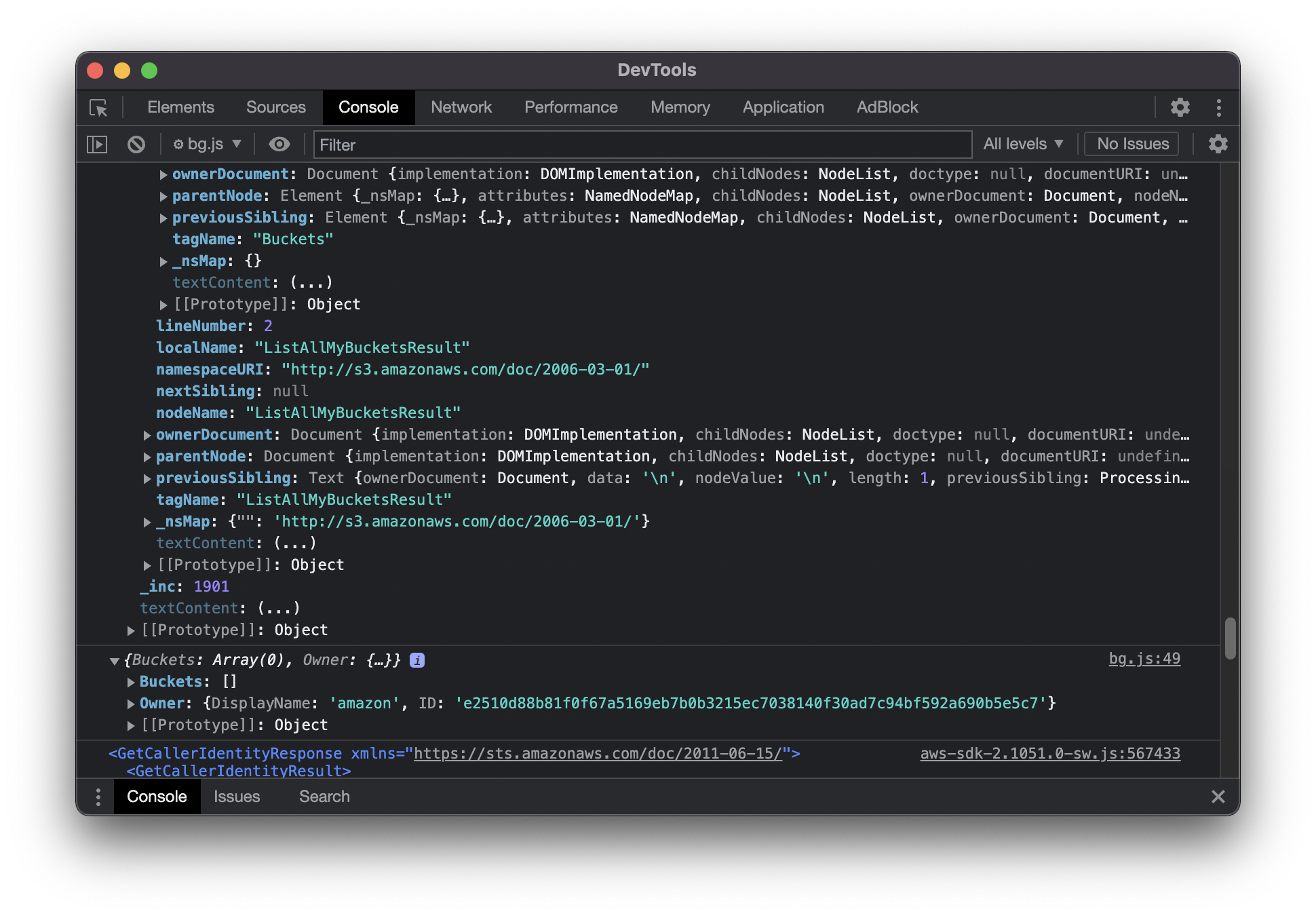
This one hurt my head. After debugging for probably a few hours, I found the issue. During the process of constructing the response in a clean format, the SDK requests the properties Element.firstElementChild and Element.nextElementSibling from the parsed object, however xmldom had not yet implemented these properties and so the iterators were silently failing.
After having a look at the xmldom library to investigate whether it could be easily patched, I instead simply implemented these properties as methods directly and replaced the SDK code which accesses these properties with my implementation, as shown below:
function getFirstElementChild(xml) {
for (var i = 0; i < xml.childNodes.length; i++) {
if (xml.childNodes[i].hasOwnProperty('tagName')) {
return xml.childNodes[i];
}
}
return null;
}
function getNextElementSibling(xml) {
var foundSelf = false;
for (var i = 0; i < xml.parentNode.childNodes.length; i++) {
if (xml.parentNode.childNodes[i] === xml) {
foundSelf = true;
continue;
}
if (foundSelf && xml.parentNode.childNodes[i].hasOwnProperty('tagName')) {
return xml.parentNode.childNodes[i];
}
}
return null;
}
After all the above changes were made, I was able to produce a version of the version 2 SDK which, from all the tests I’ve made, seems to work as intended within a service worker context.
I’ve made a version of the service worker-compatible SDK available on GitHub, should you want to compile your own. Refer to the official docs for specific compilation options, as they should work the same.
I got pretty close to abandoning this experiment, but I’m glad I persisted. I learned a lot about the internals of the SDK and got a working alternative in the end. If you liked what I’ve written, or want to tell me how terrible of an idea this was, reach out to me on Twitter at @iann0036.